Large language models have gone from research labs to everyday products in just a few years. Founders, product managers and design leads now hear questions like “what is an LLM” in investor meetings and customer calls. Understanding the basics behind these models isn’t about trendy tech — it helps teams make smart decisions about where to invest, what features to build and how to design interactions that people can actually use.
This article breaks down what large language models are, how they work, why they matter for early‑stage companies, and what practical steps teams can take to build with them. Throughout the piece we’ll talk about natural language processing, artificial intelligence, machine learning, large‑scale neural networks, and text generation. The goal is to demystify the technology while keeping a clear eye on value for users and businesses.
What does “LLM” mean in the context of artificial intelligence?
Language models have existed for decades, but earlier versions were small and limited. At their core, language models predict the next token in a sequence. Given a sentence like “It’s raining cats and ____,” a model predicts that the next word is “dogs”. Traditional models looked only at a few words around the blank. Large language models extend this idea to enormous corpora and longer contexts. They build a statistical representation of language using billions of parameters and millions or billions of words. This scale allows them to answer questions, translate languages, draft emails or write code by predicting sequences of tokens that fit the input prompt.
Large language models are part of machine learning. Machine learning refers to algorithms that improve their performance by learning from data rather than being explicitly programmed. Deep learning is a subset of machine learning that uses layered neural networks; large language models belong to this category. Deep networks with many layers and billions of parameters are trained on extensive text datasets, enabling them to model language patterns and semantics. Natural language processing (NLP) is the umbrella term for techniques that work with human language, and large language models are the current state‑of‑the‑art approach for many NLP tasks.
Why size matters

The “large” in large language model refers to both the volume of training data and the number of parameters in the neural network. Models such as GPT‑3 contain around 175 billion parameters, and more recent systems like GPT‑4 are reported to use even more. Training these models requires running computations across vast datasets — billions or trillions of tokens — which is only possible with powerful hardware and distributed computing.
Larger models tend to develop richer representations of language and exhibit emergent capabilities such as code generation and complex reasoning. However, size comes at a cost: compute bills and environmental impact rise sharply. Training GPT‑3 in 2020 was estimated to cost between $500 000 and $4.6 million depending on hardware and optimisationcudocompute.com. Estimates for GPT‑4 suggest training costs exceeding $100 million. The choice of model size therefore has real budget implications for startups. Bigger isn’t always better; many use cases can be served by smaller, fine‑tuned models that cost less to run.
Key terms
- Large language model: A neural network trained on a massive corpus of text that can generate or interpret human language. Cloudflare’s definition emphasises that LLMs are trained on huge sets of data and built on deep learning, specifically transformer models. They use learned word embeddings to represent language in high‑dimensional space, allowing them to respond to natural human prompts.
- Deep learning & large‑scale neural networks: Layers of interconnected artificial neurons transform inputs into outputs. The number of layers and parameters dictates the model’s capacity. For example, GPT‑3 uses 96 layers and has 175 billion parameters. These parameters capture statistical relationships in the data.
- Transformer architecture: Introduced in 2017, the transformer relies on self‑attention to consider the entire context of an input sequence. Unlike earlier models that processed tokens in order, transformers let each token “pay attention” to all others. This makes them particularly effective for language tasks where long‑range dependencies matter.
- Semantic understanding: Although these models don’t truly “understand” language, they capture patterns that approximate meaning. They map words and phrases into vector spaces, grouping similar concepts together. This allows them to provide answers that appear contextual and coherent.
How large language models work
Understanding how large language models operate helps product leaders evaluate what they can and can’t do. In this section we move from basic machine learning to neural networks, transformers, training regimes and model behaviour.
From machine learning to deep learning
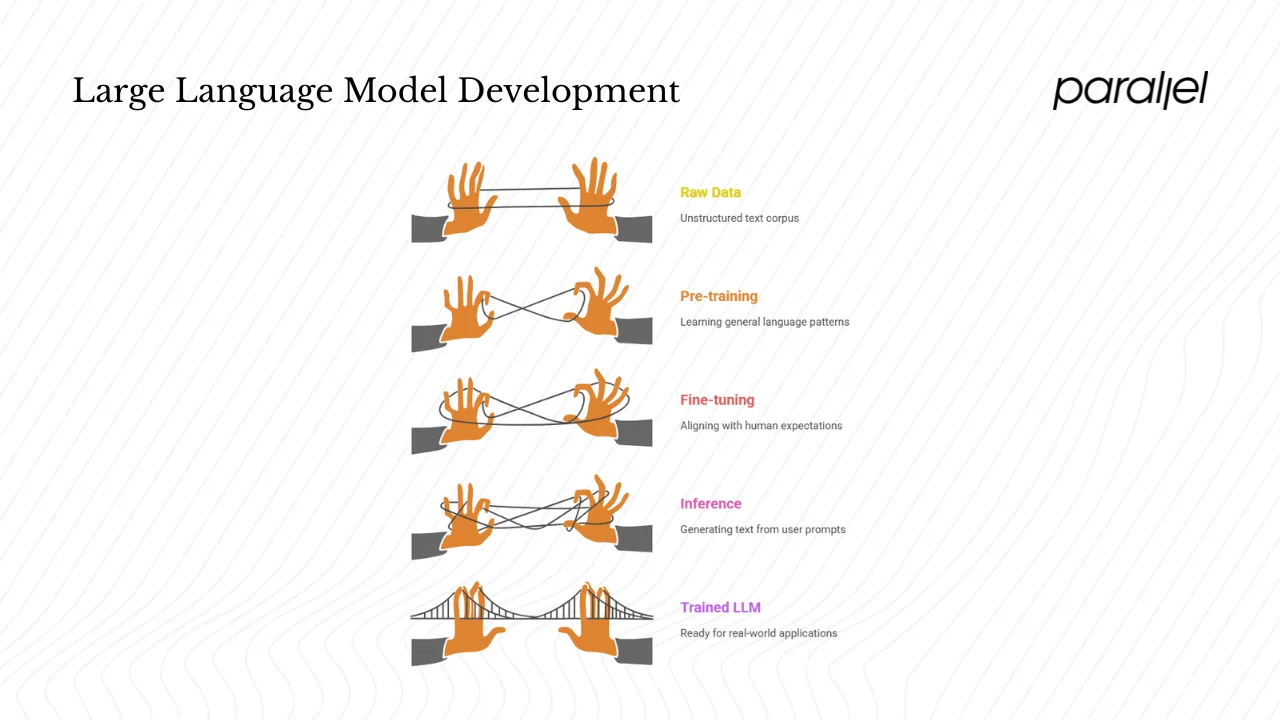
Machine learning involves supplying examples (inputs and outputs) to an algorithm so it can learn to generalise patterns. In supervised learning, the algorithm adjusts its internal parameters to minimise the difference between its predictions and the correct outputs. Deep learning amplifies this idea with multiple layers of processing. Each layer learns increasingly abstract representations: the first layer might detect word fragments; later layers combine fragments into words, phrases and concepts.
A neural network is composed of neurons organised into layers: an input layer, several hidden layers and an output layer. Each neuron performs a mathematical function on its inputs, applies a bias and activation, and passes the result to the next layer. Weights and biases are the network’s parameters. During training, backpropagation adjusts these parameters to minimise error across millions of examples. Modern generative models have many layers and billions of parameters, enabling them to capture complex dependencies in language.
Transformer architecture and attention
The breakthrough that unlocked the current wave of language models is the transformer. Traditional recurrent networks processed tokens sequentially, which made it hard to capture long‑range context. Transformers use a mechanism called self‑attention, allowing each token to weigh its relationship to every other token in the sequence. Nielsen Norman Group explains that in transformers, “each word is aware of all the other words in the passage”. This awareness lets the model consider the whole sentence or paragraph when predicting the next token, which leads to coherent responses.
Transformers also process tokens in parallel, making them more efficient to train on modern hardware. They consist of encoder and decoder blocks that apply attention, linear transformations and normalisation. The ability to scale these blocks is why large language models can grow to billions of parameters without hitting the same bottlenecks as earlier architectures.
Training: data and fine‑tuning
Training a large language model involves two phases. First, pre‑training exposes the model to a large corpus of text so it can learn general language patterns. Sources include web crawls, books, news articles and code repositories. During pre‑training the model’s objective is to predict the next token, forcing it to develop representations of grammar and semantics. After pre‑training, models are often fine‑tuned on narrower datasets or through reinforcement learning from human feedback. This second phase shapes the model’s behaviour to align with human expectations and domain requirements. Cloudflare notes that LLMs are often further tuned via prompt tuning or instruction tuning for specific tasks.
Because training is expensive, most startups don’t pre‑train models from scratch. Instead they use pre‑trained models from open‑source projects or commercial providers and finetune them on their own data. This approach saves compute and time while still achieving domain‑specific performance. Even fine‑tuning can be resource‑intensive if datasets are large; careful curation and cleaning of data is essential.
Inference: what happens during text generation
When a user sends a prompt to a large language model, the model processes the input and generates a probabilistic distribution over the next possible tokens. Generative models are fundamentally sequence‑prediction machines. They predict multiple candidate tokens with associated probabilities and then sample from this distribution to construct a response. Temperature and top‑k parameters adjust how conservative or creative the sampling is. Lower temperatures make the model choose the most likely next word, producing safer but sometimes dull output; higher temperatures allow for more diverse results but increase the risk of irrelevant or incorrect responses.
This generation process is not deterministic; the same prompt can yield different responses, which designers must account for in user experiences. The model is not retrieving facts from a database — it is constructing answers based on learned patterns. It has no inherent concept of truth. As a result, LLM outputs can be convincing but inaccurate. The model’s “understanding” is statistical rather than semantic.
Limitations and risks
Large language models have impressive capabilities, but they also come with significant limitations:
- Hallucinations: Generative models often produce plausible but incorrect information. Nielsen Norman Group defines hallucinations as instances where the system generates output that seems plausible but is incorrect or nonsensical. In an example, ChatGPT falsely attributed quotations to journalists in 76% of cases and seldom indicated uncertainty. Even specialised legal tools have produced incorrect information in roughly one out of six queries. Hallucinations arise because the model’s goal is to output statistically likely sequences. If the training data contains errors or the prompt leads into uncharted territory, the model may fabricate details.
- Bias: Models learn from the data they are fed. If the corpus contains biased language or under‑representation of certain groups, the model reproduces those biases in its outputs. Without careful curation and bias mitigation, outputs may reinforce harmful stereotypes.
- Compute and cost: Training and running large models is expensive. GPT‑3’s training costs ranged from roughly half a million to several million dollars. GPT‑4’s training cost is reported to exceed $100 million. Every inference also consumes compute resources, which can add up when serving thousands of users.
- Latency: Large models are slower to respond, which can degrade user experience. Response time matters; delays lead to frustration and drop‑offs.
- Data privacy: Models trained on public data may inadvertently memorise sensitive information. Cloudflare warns that user‑facing applications can be manipulated via malicious inputs and may expose confidential data because models use inputs to further train themselves. Uploading private documents to a model without proper controls can risk leaks.
- Security and misuse: Attackers can craft prompts to make models divulge hidden instructions or produce harmful content. Guardrails and prompt sanitisation are essential to reduce risk.
Understanding these limitations is key for making responsible product decisions. Teams should validate outputs, inform users about risks and design feedback mechanisms to catch errors early.
Why large language models matter for startups and product/design teams
1) Strategic opportunities
Large language models enable capabilities that were out of reach for small teams a few years ago. Chat interfaces that answer customer questions, semantic search that understands intent, automated summarisation, code generation — these features open new product categories. Cloudflare notes that LLMs can write essays, poems, sentiment analyses, code and more. Because commercial platforms like OpenAI, Anthropic and Mistral offer APIs, even early‑stage startups can integrate advanced language technology without building infrastructure from scratch. This can differentiate a product in crowded markets.
We’ve seen early‑stage clients at Parallel incorporate language models to automate support responses, generate marketing copy and power internal knowledge bases. The key is choosing use cases where generative text adds clear value. A chatbot that answers common questions frees up human support teams. A semantic search feature can help users find documentation more quickly. However, not every feature needs text generation. The model should serve a specific goal, not be wedged in because of hype.
2) Impact on product and design
The shift from clicking buttons to conversing with a system reshapes product and design work. Jakob Nielsen describes intent‑based outcome specification as the third major user interface shift. Instead of issuing precise commands, users express their goals in plain language. This has profound implications for designers:
- Designers become prompt engineers: The current interaction pattern requires users to craft effective prompts. Nielsen notes that this new role emerged because chat interfaces have deep usability problems and often need specialists to coax the right response. Product teams must decide whether to offload prompt construction to users or provide pre‑built prompt templates.
- Conversational interfaces reduce fixed flows: Traditional interfaces guide users through fixed steps. In chat‑based interfaces, the “prompt is the UI.” Designers must think about language patterns, context and error handling. They must also accommodate users who are less articulate — research shows that about half the population may struggle to produce effective prompts.
- Mental models differ: Users bring expectations from search engines and command‑based interfaces. Pew research in late 2024 found that 81% of U.S. workers reported little or no use of artificial intelligence at work. Over a third who don’t use chatbots said there wasn’t a use case for them. Designers cannot assume familiarity. They need to support discovery and teaching within the interface.
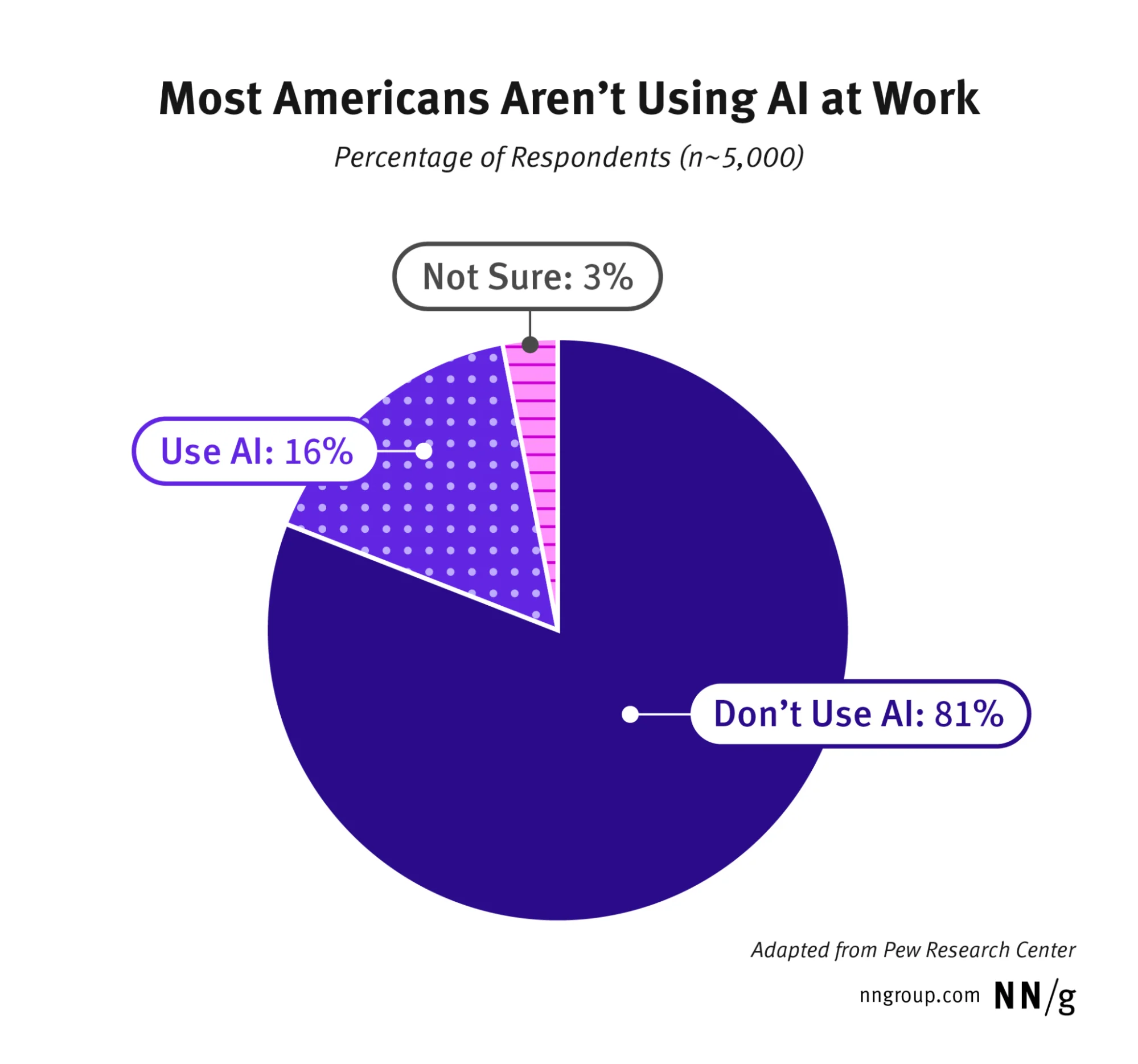
- User perception of value: In the same survey, most workers who used chatbots employed them for information seeking (57%), editing (52%) and drafting (47%)nngroup.com. Far fewer used them for ideation or coding. This suggests that early features should align with simple, high‑frequency tasks. As competence grows, more complex use cases can follow.
3) Operational and technical implications
From an operations perspective, using large language models introduces new requirements:
- Cost management: API calls are priced per token. Fine‑tuning and self‑hosting involve compute expenses and GPU availability. Cost controls such as caching, rate limiting and smaller models are critical.
- Infrastructure: Running models in production requires scalable compute and monitoring. Latency targets may dictate which model size is acceptable. Using retrieval‑augmented generation (RAG) — adding a search component that supplies relevant documents to the model — can improve factual accuracy while keeping model sizes manageable.
- Dataset sourcing and preparation: Fine‑tuning requires relevant, high‑quality data. Teams must ensure they have legal rights to use the data and avoid sensitive or biased content. Data should be cleaned and structured for training.
- Maintenance: Models drift as user behaviour and data change. Versioning and monitoring systems are needed to track model outputs, detect regressions and manage updates. Startups need a feedback loop with users to identify failure modes early.
Example use cases
Here are some practical applications we’ve implemented or seen clients pursue:
- Customer support assistant: A conversational agent responds to frequently asked questions and hands off to humans when confidence is low. It reduces response time and escalates only complex issues.
- Internal knowledge search: An LLM with retrieval‑augmented generation surfaces policies, project documentation and past meeting notes. It answers natural language queries and cites sources.
- Content generation: Marketing teams use models to draft blog posts, product descriptions and social media snippets. Editors refine the output, treating the model as a starting point rather than a final writer.
- Code generation: Developers use models such as GitHub Copilot to generate boilerplate code or unit tests. This speeds up routine programming tasks and reduces context switching.
The common thread is that language models augment teams by handling repetitive or tedious tasks, freeing people to focus on strategic work.
Design and UX considerations specific to large language models
1) The prompt‑driven interface
The current crop of language‑powered interfaces are essentially chat windows. Users type instructions or questions; the model responds with text. This shift means that the “prompt” has become the primary user interface. Designers must think about how to structure prompts, provide guidance and reduce the cognitive load on users. Without clear scaffolding, novice users can get stuck or produce poor prompts, resulting in unsatisfactory answers. Nielsen warns that half of people may not be articulate enough to get good results under today’s chat interaction.
To address this, many products offer preset actions (for example, “Summarise this document” or “Draft a support reply”) that generate appropriate prompts behind the scenes. This approach lowers the barrier to entry while still leveraging the model’s flexibility. Progressive disclosure is useful: start with simple options and reveal more advanced controls as users gain confidence. Combining chat with traditional UI elements — buttons, drop‑downs, interactive cards — can ground the conversation and reduce ambiguity.
2) Trust, feedback and transparency
Confidence and trust are hard won in generative systems. Models may produce confident but incorrect answers, leading users to misjudge their accuracy. Nielsen Norman Group suggests that hallucinations create design challenges and user distrust. To mitigate this, interfaces should:
- Surface uncertainty: Display probabilities, confidence scores or warning labels when the model may be wrong. Provide citations or links to sources when available. Indicating that an answer is a best guess, not a fact, can prevent over‑reliance.
- Enable feedback: Let users flag incorrect responses, suggest corrections or ask follow‑up questions. Feedback not only improves the model through reinforcement learning but also helps users feel in control.
- Provide undo and edit: If the model writes an email, allow users to edit the draft before sending. If it retrieves data, let them choose whether to trust it.
- Align visual tone with capability: People anthropomorphise conversational systems when they appear human‑like. Overly human avatars can inflate expectations. A neutral presentation reduces the risk of misinterpretation.
Transparency also applies to training data and biases. Inform users about the data sources and limitations. Avoid making claims that the model understands or knows things. Set expectations clearly in onboarding and help content.
3) Onboarding and user education
Because many users are new to language models, onboarding plays a crucial role. Pew research shows that 81% of U.S. workers do not use artificial intelligence at work. This means most people are unfamiliar with prompt‑driven systems. Good onboarding should:
- Explain capabilities and limits: Tell users what the model can and cannot do. Clarify that it generates text based on patterns rather than retrieving facts.
- Provide examples: Show sample prompts that produce useful outputs. Offer templates for common tasks. Use tooltips or contextual hints to guide the first few interactions.
- Encourage experimentation: Emphasise that outputs can be iterated. Let users refine prompts and see how the model responds differently.
- Educate about privacy: Remind users not to input confidential or sensitive data, as the model may retain or reveal it.
Designers must assume that users lack mental models of how the system works and gradually build their understanding through interactive help and progressive disclosure.
4) Metrics and evaluation
Measuring the success of language‑based features is challenging. Traditional metrics like click‑through or time spent may not capture conversational quality. Consider metrics such as:
- User satisfaction: Collect qualitative feedback on whether the output met user expectations. Quick surveys or thumbs‑up/thumbs‑down buttons can capture sentiment.
- Task completion: Measure whether users achieve their goals faster or with less friction compared to manual processes. For example, track how long it takes to resolve a support ticket with an assistant versus without one.
- Intervention rate: Monitor how often humans need to intervene or correct the model. A high intervention rate indicates poor performance or misalignment with user needs.
- Retention and adoption: Determine whether users continue to use the feature over time. If usage drops after the novelty wears off, it may indicate a mismatch between promise and value.
6) Ethical design and inclusiveness
Large language models inherit biases and gaps from their training data. Designers must think proactively about fairness and inclusiveness. Avoid features that amplify stereotypes or exclude certain communities. Include diverse user groups in testing to catch issues. Multilingual support matters: many products serve global audiences, and models can be tuned to understand multiple languages. Accessibility is also essential; conversational interfaces should support screen readers, speech input and other assistive technologies.
Building or integrating a large language model feature: a practical roadmap
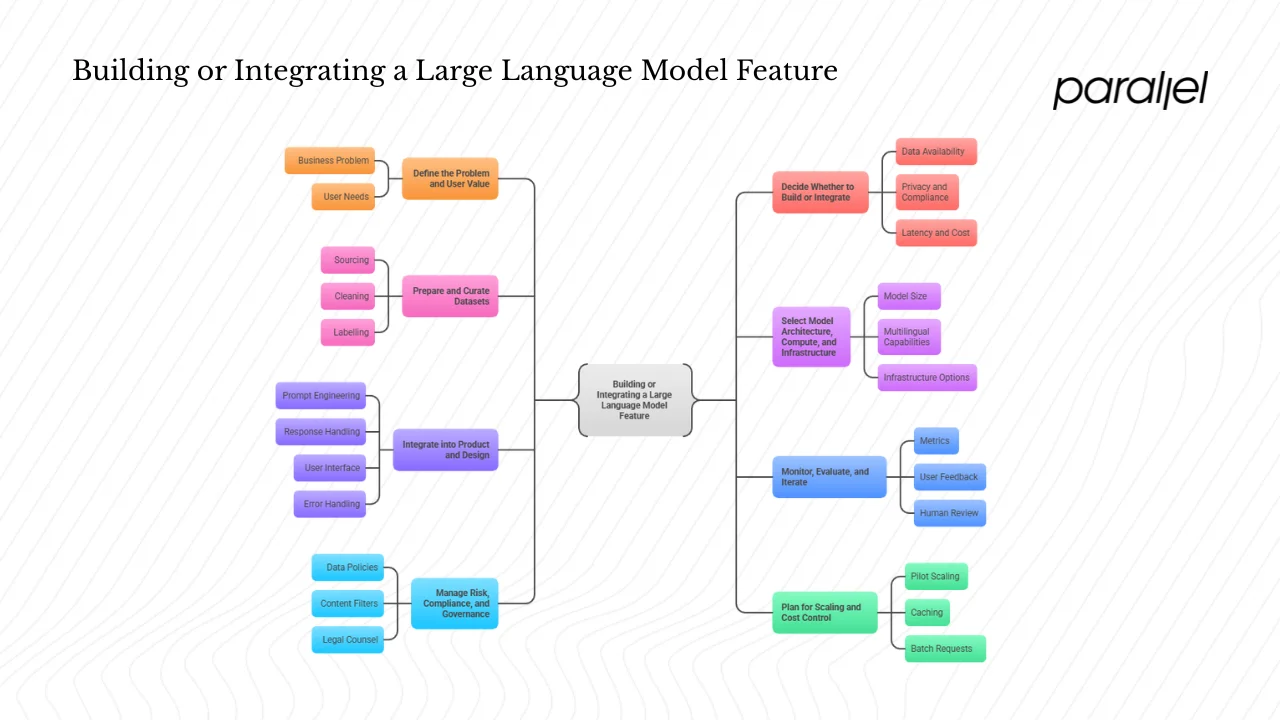
1) Define the problem and user value
Before writing a line of code or calling an API, clarify the business problem. What user needs does the model address? For example, are you trying to reduce support wait times, help marketing craft personalized messages, or give engineers a tool to auto‑generate unit tests? Map the proposed feature to your company’s goals and product strategy. A clear problem definition prevents scope creep and helps determine whether a large language model is the right tool at all.
2) Decide whether to build or integrate
Startups rarely train models from scratch due to cost and complexity. Most teams integrate pre‑trained models via APIs from providers like OpenAI, Anthropic, Google or open‑source communities. Building your own model involves selecting architecture, acquiring massive datasets and provisioning expensive hardware. As noted earlier, training GPT‑3 cost up to $4.6 million, while GPT‑4’s costs exceeded $100 million. Fine‑tuning an existing model on your domain data provides a middle ground: you benefit from the pre‑trained knowledge while adapting behaviour to your needs.
Factors to consider:
- Data availability: Do you have enough high‑quality examples to fine‑tune? Is the data legally cleared for training? Fine‑tuning small models requires less data than training large ones.
- Privacy and compliance: If you’re in a regulated industry, you may need on‑premises deployment or strict data handling. Some providers offer privacy‑preserving options.
- Latency and cost: Using a hosted API is convenient but may have higher per‑request costs. Self‑hosting can reduce inference cost but increases operational complexity. Consider expected usage volume and performance requirements.
3) Prepare and curate datasets
Fine‑tuning demands high‑quality, domain‑specific datasets. Steps include:
- Sourcing: Collect data from reliable sources like knowledge bases, internal documents, support logs or curated public datasets. Avoid scraping random web pages to reduce noise and bias.
- Cleaning: Remove duplicates, irrelevant content and sensitive information. Normalise formatting and correct typos. Balanced representation matters to avoid skewing the model.
- Labelling: For tasks like classification or summarisation, label data with correct outputs. For open‑ended generation, compile example prompts and desirable responses.
4) Select model architecture, compute and infrastructure
When choosing a model, weigh size against cost and latency. Smaller models like Llama 2 7B may be sufficient for simple tasks, while more complex use cases may require larger models. Consider whether you need multilingual capabilities or domain‑specific versions (e.g., code‑oriented models). For infrastructure, evaluate serverless options that scale automatically versus dedicated GPU instances. Cloud providers and startups offer managed platforms for running models at the edge, reducing latency for global users.
5) Integrate into product and design
Integration is where technical work meets user experience. Key considerations:
- Prompt engineering: Craft prompts that reliably elicit the desired behaviour. For example, including the instruction “Respond in a concise and friendly tone” can guide the model. Keep prompts consistent across similar tasks to minimise unpredictable outputs.
- Response handling: Parse the model’s output and convert it into actionable content. If using retrieval‑augmented generation, attach citations or footnotes. Provide fallback messages when the model is uncertain or fails.
- User interface: Decide how the model’s responses appear — inline in a chat, inside panels or as suggestions. Maintain clarity about which content is machine‑generated.
- Error handling: Design flows for when the model misinterprets a request. Offer corrections, clarifications or alternatives.
6) Monitor, evaluate and iterate
Deployment is the start of a long feedback cycle. Monitor the model’s behaviour using metrics discussed earlier. Collect user feedback and analyse failure cases. Incorporate human review when stakes are high. Fine‑tune the model as new data arrives. For example, update support assistants with new product information so they stay accurate. Model performance will drift over time as language and user expectations change; plan regular evaluations.
7) Manage risk, compliance and governance
Large language models must be used responsibly. Establish policies for data collection, storage and usage. Ensure that users know not to submit confidential data unless you have secure processing in place. Put in place content filters to block harmful or biased outputs. Keep a human‑in‑the‑loop for decisions with legal, financial or health implications. Consult legal counsel on compliance with regulations such as GDPR or HIPAA where applicable.
8) Plan for scaling and cost control
Start with a small pilot and scale gradually. Use caching to store common responses. Batch requests or stream outputs to reduce costs. Monitor API usage and adjust model parameters to balance quality and budget. Consider open‑source models if long‑term usage costs are prohibitive; they allow running on your own infrastructure and avoiding per‑call fees.
What’s next: trends to watch
The pace of advancement in language models continues to accelerate. Here are developments to keep an eye on:
- Model efficiency: Research is focusing on making models smaller and faster without losing capability. Techniques like quantisation, pruning and distillation reduce parameter counts and compute requirements. LoRA (Low‑Rank Adaptation) allows teams to adapt models with fewer trainable parameters, lowering fine‑tuning cost.
- Multi‑modal models: New systems handle not just text but images, audio and video. GPT‑4 is classified as multimodal because it can process images. Future models may integrate vision, speech and gesture, opening the door to assistants that can see and hear as well as read and write.
- Retrieval‑augmented generation: Combining language models with external search or knowledge bases improves accuracy. Instead of relying solely on parameters, the model retrieves relevant documents and uses them to craft responses. This approach reduces hallucinations and keeps models up to date.
- Democratisation of modelling: Open‑source models like Llama 3 and Mistral are making advanced capabilities accessible. Tools and platforms simplify fine‑tuning, lowering the barrier for startups. Cost reductions and hardware advances will further open the field.
- User interaction evolution: Voice and gesture input may replace or augment typed prompts. Agents that execute tasks autonomously (e.g., scheduling meetings, ordering supplies) are emerging. Interfaces will likely blend conversational and traditional elements.
- Governance and ethics: Policymakers and industry groups are developing frameworks to address safety, bias and accountability. Product and design teams must engage in these discussions, ensuring that features align with social values and regulations.
Conclusion
Large language models represent a significant shift in how we build and interact with technology. At a fundamental level, they are statistical prediction machines that generate plausible sequences of text. They enable new product categories like conversational assistants, semantic search and automatic content generation. For startup leaders, the question “what is an LLM” isn’t academic — it’s tied to product strategy, design, cost and risk. Adopting language models requires careful problem definition, data stewardship, thoughtful design and ongoing evaluation. The technology’s complexity should not obscure the core principle: deliver real value to users through clear, trustworthy and accessible experiences. With a grounded approach, teams can harness the potential of these models while mitigating their risks.
FAQ
1) What does LLM mean in artificial intelligence?
In the context of artificial intelligence, “LLM” stands for large language model. It refers to a machine learning model, built on deep neural networks and trained on vast text corpora, that can generate and interpret human language. These models use transformer architectures and self‑attention to understand context.
2) Is ChatGPT a large language model?
Yes. ChatGPT is an application built on top of the GPT family of large language models developed by OpenAI. GPT‑3 uses 175 billion parameters, and GPT‑4 reportedly contains even more. ChatGPT fine‑tunes these models to provide conversational answers and is continually refined using human feedback and other training techniques.
3) What is an example of a large language model?
Examples include OpenAI’s GPT‑3 and GPT‑4, Google’s Bard (also known as Gemini), Meta’s Llama series and Microsoft’s Copilot. These systems are trained on massive datasets and use transformer architectures. They perform tasks such as text generation, translation, code completion and question answering. Some models are domain‑specific: for instance, DeepSeek is trained on code, and there are specialized biomedical models.
4) How do large language models differ from traditional machine learning models?
Traditional machine learning models often have far fewer parameters and are designed for specific tasks, like classifying images or recognising speech. Large language models are general‑purpose text models with billions of parameters, trained on diverse corpora. They can perform many language‑related tasks without task‑specific training. Their size and architecture (transformers with self‑attention) enable them to capture context and semantics at scale.
5) What is the difference between LLM and JD?
Outside of computing, “LL.M.” refers to the Master of Laws degree, an advanced legal qualification that lawyers may pursue after earning a Juris Doctor (J.D.). A J.D. is the first professional law degree required to practise law in the United States, typically completed after an undergraduate degree. Admission to an LL.M. program usually requires having a J.D. or an equivalent foreign law degree. LL.M. programs specialise in specific legal areas and take one year of full‑time study, while J.D. programs are broader and take three years. In the context of artificial intelligence, however, LLM means a large language model.

check out these related blogs