In the last eighteen months, entrepreneurs and product folks have watched artificial‑intelligence projects go from experiments to boardroom priorities. Market data shows that nearly all Fortune 500 companies already use artificial‑intelligence technologies and that around 90 percent of businesses rely on artificial‑intelligence solutions to stay competitive. Yet many founders, designers and product managers are still unsure about what a neural network is and why they should care.
Understanding this concept is no longer optional. It helps you ask the right questions when engineers propose new features, decide when to invest in data infrastructure, and shape experiences powered by smart systems. In this article I’ll explain in plain language how neural networks work, why they matter to early‑stage product teams, and how to think about them without getting lost in jargon.
Setting the scene: from artificial intelligence to deep learning
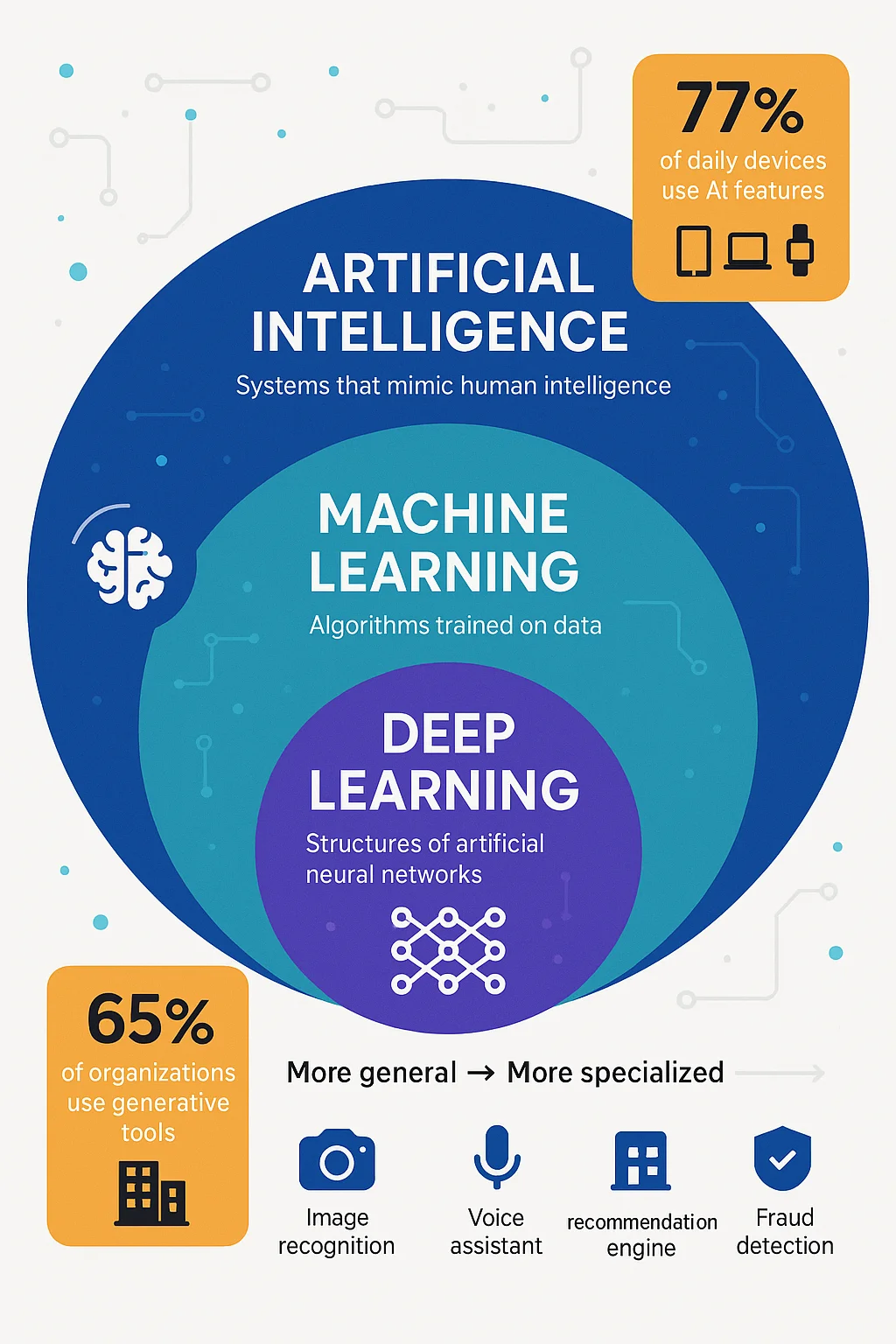
Artificial intelligence (AI)—the broad field concerned with building machines that can solve problems humans usually solve—is now everywhere. Researchers, designers and executives alike are experimenting with tools that simulate human learning and reasoning. Within artificial intelligence sits machine learning, a family of methods that allow algorithms to learn patterns from data rather than being explicitly programmed. Machine learning is the workhorse behind most modern applications: it powers suggestion engines, personalized feeds and fraud detection.
A neural network is one approach within deep learning, a subset of machine learning that stacks many processing steps. Each stack, called a layer, transforms its inputs into more abstract representations. Deep learning became practical because we now have vast amounts of data and cheap graphics‑processing units; together they allow models to learn complex patterns from images, speech and text. With 77 percent of the devices we use daily incorporating artificial‑intelligence features and generative tools being used in 65 percent of organizations, product and design teams need to know when to deploy such models and when to pick simpler techniques.
For non‑technical stakeholders, it helps to see how these terms relate:
- Artificial intelligence: any computer‑based system that performs tasks we associate with human reasoning, learning, or perception.
- Machine learning: a branch of artificial intelligence where models learn from data. Algorithms tune themselves by reducing the difference between predicted outputs and actual labels.
- Deep learning: a group of machine‑learning techniques that use multi‑layered neural networks. Deep refers to the number of hidden processing layers, not the sophistication of the ideas.
Teams should consider neural networks when dealing with unstructured data (images, speech or natural language), when the problem involves complex pattern recognition, or when simple rules and regression methods fall short. They are less appropriate for problems with small datasets, strict interpretability requirements or tight computational budgets.
Before diving deeper, it’s natural to pause and ask what this model means in the broader context. In practical terms, a neural network is the mechanism that deep learning uses to transform raw sensory inputs into predictions or decisions. Appreciating this relationship between the wider artificial‑intelligence field and the specific mechanism of neural networks will help you decide whether these models are appropriate for your product.
What is a neural network?
So what is neural network exactly? A neural network is a machine‑learning model composed of interconnected nodes (often called neurons) arranged in layers. Each neuron receives inputs, applies a weight (which shows how strongly it influences the next neuron) and a bias (which shifts the activation threshold), and passes the result through a non‑linear function. The Interaction Design Foundation describes neural networks as “layers of artificial neurons that process and transmit information between each other”, each neuron having a weight and a threshold (bias) that determines how much it contributes to the next layer’s output. TechTarget adds that neural networks are machine‑learning models designed to process data in a way that mimics the function and structure of the brain. These networks are part of deep learning and are widely used in image recognition, predictive modelling, decision‑making and natural language processing.
Put simply, a neural network learns to map inputs to outputs by adjusting the strengths (weights) of connections between neurons. During training, the network receives example data (e.g., labelled photos or sentences) and gradually tunes its weights to minimize the difference between its predictions and the correct answers. Once trained, it can process new data and make predictions or decisions based on learned patterns. The terminology may sound technical, but the underlying principles are intuitive: layers of simple mathematical functions combining to approximate very complex relationships.
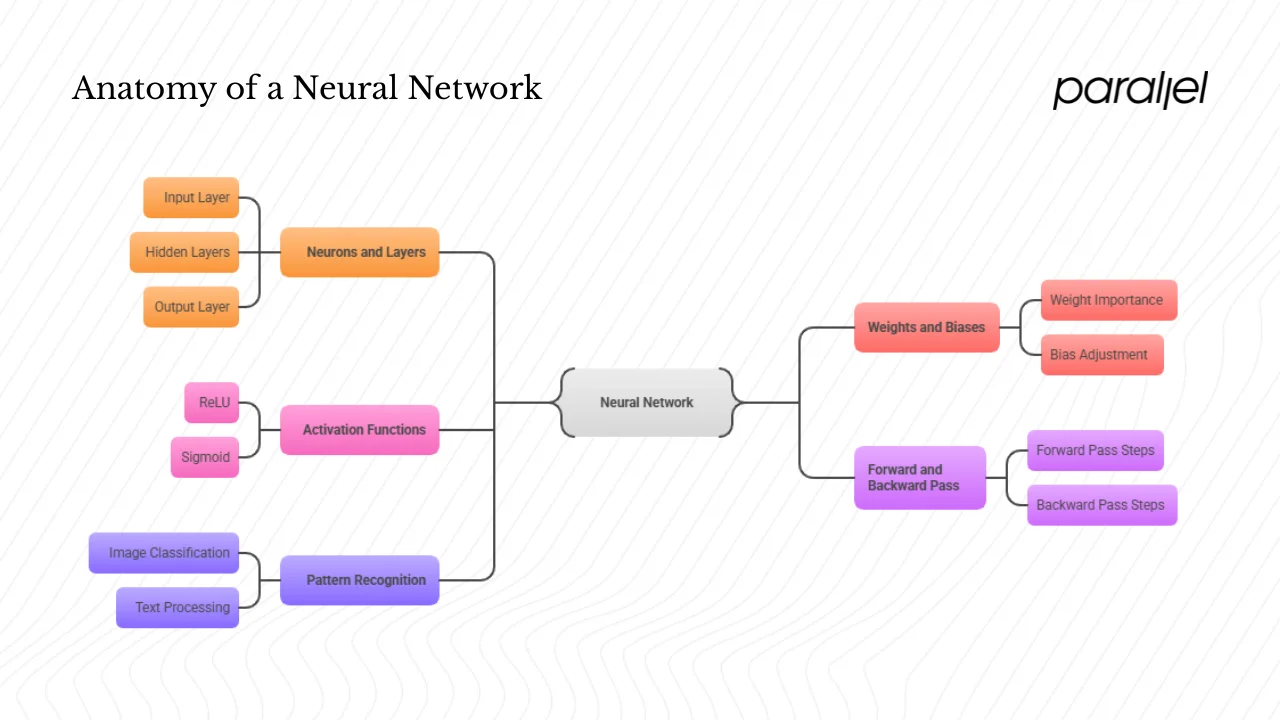
Core terminology
- Neurons (nodes): simple processing units that sum their inputs, add a bias and apply a non‑linear transformation. Inspired by biological neurons, they pass signals to other neurons.
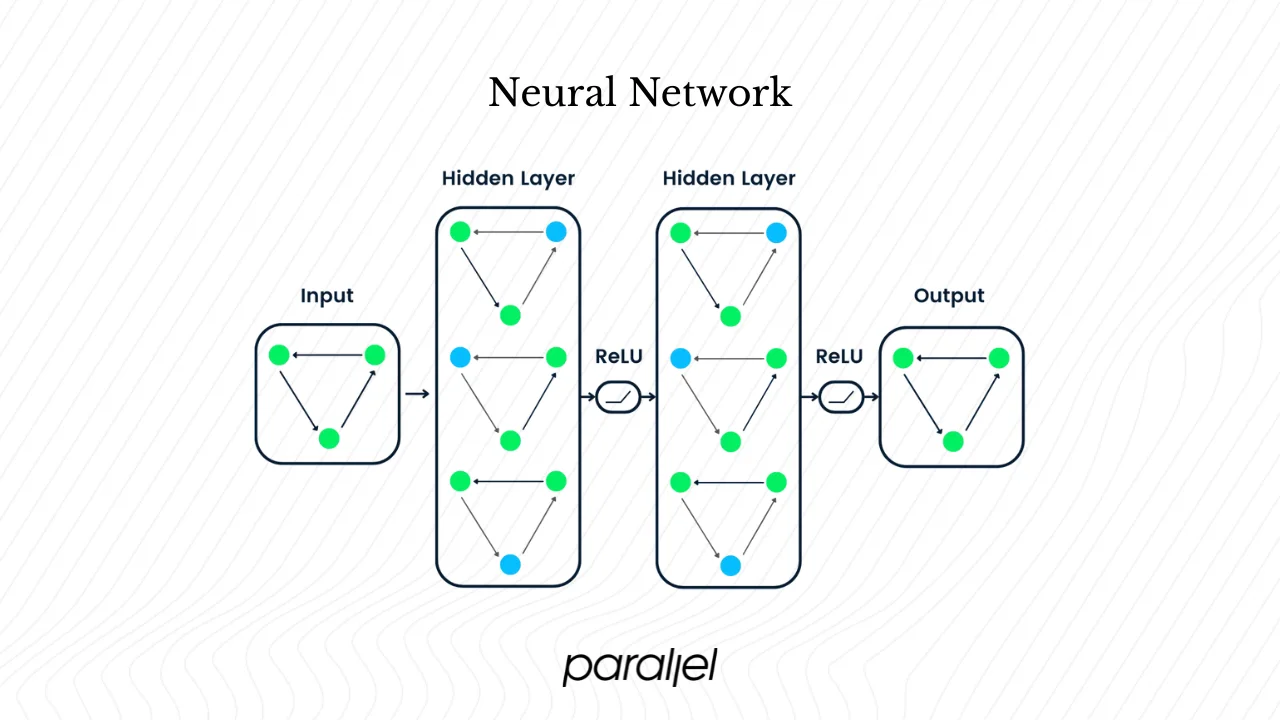
- Layers: groups of neurons stacked sequentially. A typical network includes an input layer, one or more hidden layers, and an output layer. Simple networks have fewer hidden layers; deep networks have many.
- Weights and biases: tunable parameters that determine how much influence one neuron’s output has on the next and shift the activation threshold. They are adjusted during training.
- Activation functions: non‑linear functions (such as ReLU or sigmoid) applied after the weighted sum plus bias. They allow the network to model complex, non‑linear patterns.
- Forward pass: the process of passing input data through the layers to produce an output.
- Backpropagation: the method for training the network by propagating the error backwards and updating the weights and biases via gradient‑descent‑style optimization.
By introducing these terms early, teams build a shared vocabulary. When a data scientist proposes “increasing the number of hidden layers” or “tuning the learning rate”, founders and designers can ask informed questions rather than nodding silently.
Anatomy of a neural network: components and how it works
1) Neurons and layers
The fundamental building block of a neural network is the neuron (or node). Inspired by biological neurons, each artificial neuron receives inputs from the previous layer, multiplies each by a weight, adds them together, and applies a bias. The output then flows through a non‑linear activation function. Networks organize these neurons into layers. The input layer receives raw data (pixel values in an image, word embeddings in a sentence). One or more hidden layers transform the data into more abstract representations. The output layer produces the final prediction. Deep networks have many hidden layers; shallow networks have just one.
You can picture a neural network like a team passing signals down a chain. The first person receives raw information, packages it and hands it to the next person, who packages it further, and so on. Each hand‑off either amplifies or dampens the signal depending on the learned connection strengths. Eventually the last person on the team announces a result. The power of neural networks comes from the fact that each layer learns to extract increasingly complex features without manual intervention.
2) Weights and biases
Neurons aren’t valuable on their own; their power comes from adjustable weights and biases. A weight tells the network how important a particular input is for a given neuron. In the GeeksforGeeks description, weights find how much influence each input has on the network’s final output. During the forward pass, inputs are multiplied by their corresponding weights and then passed through an activation function. Biases are additional parameters that adjust the output of a neuron; they allow neurons to activate even when the weighted sum is too low.
Training involves updating these parameters. When the network makes a wrong prediction, the backpropagation algorithm calculates gradients (partial derivatives of the error with respect to each parameter) and nudges the weights and biases to reduce the error. Over time, the network learns which inputs matter most and how to shift the thresholds so that it generalizes beyond the training data. Without weights and biases, a network would be a fixed, linear transformation incapable of learning complex patterns.
3) Activation functions and non‑linearity
After computing the weighted sum and adding a bias, neurons apply an activation function, introducing non‑linearity. This step is crucial. If every layer merely performed linear combinations, then even many layers would collapse into a single linear equation; the network could only learn straight lines. Non‑linear functions like ReLU (Rectified Linear Unit) output zero for negative inputs and a linear value for positive inputs, enabling models to capture complex relationships. Other functions like sigmoid map any input to a value between 0 and 1, which is useful when probabilities are needed. By stacking layers of non‑linear functions, neural networks can approximate any function to an arbitrary degree of accuracy—this is known as the universal approximation theorem.
4) Forward pass and backward pass
Training a neural network consists of two phases repeated many times: the forward pass and the backward pass. During the forward pass, input data flows through the network layer by layer and produces an output. The GeeksforGeeks description lists the steps: starting with the input layer, each neuron computes the weighted sum of its inputs, adds a bias and applies an activation function. The result becomes the input to the next layer, and this propagation continues until the final prediction.
After the forward pass, the network compares its prediction with the ground truth using a loss function (for example, cross‑entropy for classification). In the backpropagation phase, the network calculates the error gradient with respect to each parameter and updates weights and biases to reduce the loss. Optimisation algorithms like stochastic gradient descent perform this adjustment iteratively. Training requires careful tuning: too large a learning rate can cause divergence, whereas too small a rate slows convergence. Overfitting is another concern; it happens when the network learns the training data too well and performs poorly on new examples. Regularisation techniques, drop‑out layers and early stopping can help mitigate overfitting.
5) Pattern recognition and data processing
Neural networks excel at pattern recognition. As data passes through successive layers, the network learns to extract hierarchical features: edges and textures in early layers of an image classifier, then shapes, and eventually entire objects. In text processing, recurrent or transformer‑based networks track sequences, capturing grammar and context. TechTarget’s article notes that neural networks are widely used in image recognition, speech‑to‑text transcription, weather prediction and facial recognition. By adjusting weights and biases, networks generalize patterns across diverse inputs. That generalization makes them suitable for tasks where rules are hard to code manually.
For product and design teams, this means that neural networks open possibilities for handling unstructured data: understanding user intent from chat logs, categorising support tickets, or detecting anomalies in sensor readings. Unlike rule‑based systems that require explicit instruction for every scenario, neural networks can learn subtleties from examples, though they still depend on the quality and diversity of training data.
Why neural networks matter for startups and product‑design teams
Neural networks unlock new capabilities that were impractical a decade ago. They allow small teams to build suggestion engines, smart search, image classification, and generative assistants. As the DemandSage statistics show, around 90 percent of businesses adopt artificial‑intelligence solutions to stay competitive, and 77 percent of devices already include artificial‑intelligence features. Ignoring these tools isn’t prudent; customers expect more personalised and responsive experiences. Here are some reasons neural networks matter to startups:
- Handling messy data: Neural networks process images, audio and natural language effectively. For example, a feedforward network can classify spam emails by learning the frequency patterns of words, while a convolutional neural network (CNN) recognises objects in photos. These capabilities enable features like automatic moderation, visual search and speech commands.
- Creating suggestion engines: By analysing past behaviour, networks can suggest products, articles or actions that users are likely to appreciate. Recommendation engines (or suggestion engines) rely on learning complex relationships between users and items. For a streaming service, this means recommending movies similar to those a user has enjoyed; for a software product, it might mean predicting the next best action in an onboarding flow.
- Detecting anomalies: In operations, neural networks can flag unusual patterns—fraudulent transactions, machine failures, or churn signals. Because the models learn from historical data, they can spot deviations in real time.
- Improving accessibility: Speech‑to‑text, language translation and image captioning open products to wider audiences. Recurrent neural networks and transformers turn spoken language into text or translate between languages, enabling new forms of interaction.
From a strategic perspective, neural networks make data a strategic asset. Early‑stage companies often collect user interactions, but raw logs are worthless unless turned into insights. Neural networks can convert logs into predictive signals; however, they require careful data governance and infrastructure. Founders should budget for data collection, cleaning, labeling and storage. They should also recognise the compute costs: training large models might require specialized hardware or cloud services.
Design leaders must consider how neural‑network‑powered features affect user experience. Automated suggestions can delight users when they are accurate, but poorly trained models can frustrate. Transparent design—such as explaining why a suggestion was made—builds trust. Product managers should weigh the interpretability trade‑off: neural networks are often described as “black boxes.” While techniques like feature importance and saliency maps provide some insight, simpler models might be preferable when decisions must be explainable (e.g., credit approvals). Collaboration across design, engineering and data science is crucial; open discussions can uncover latent biases, data gaps and unrealistic expectations.
Types of neural networks and when to use them
Different architectures suit different problems. Understanding the varieties helps non‑specialists collaborate effectively with engineers.
- Feedforward Neural Networks (FNNs): Also called multilayer perceptrons, these are the simplest type. Information flows in one direction, from input to output. They are used for classification or regression tasks where data has no spatial or temporal structure. An example is spam email classification, where the network looks at word frequencies and outputs a spam probability. Recognising the simplicity of these architectures makes it easier to answer what is neural network when your colleagues or investors raise questions.
- Convolutional Neural Networks (CNNs): CNNs shine on spatial data—images, video, even audio spectrograms. They use convolutional layers that scan local regions, detecting edges, textures and shapes. TechTarget notes that CNNs were pivotal in ImageNet competitions and are used in applications like object detection and medical imaging. Startups building photo‑editing apps or quality‑control tools can use CNNs to automate tasks that once required human eyes.
- Recurrent Neural Networks (RNNs) and sequence models: RNNs process sequential data by maintaining a hidden state that carries information from previous steps. They are suited for time‑series forecasting, speech recognition and natural language understanding. Variants like LSTM and GRU address vanishing‑gradient problems. RNNs form the backbone of voice assistants and chatbots. More recent transformer architectures have largely replaced RNNs in language tasks, but the idea of sequence modelling remains.
- Graph Neural Networks (GNNs): When your data consists of relationships—social networks, knowledge graphs or supply chains—GNNs can learn from the connections between nodes. They are useful for recommendation on platforms where relationships matter, or for fraud detection in finance. They are more advanced and may require specialist expertise.
As a rule of thumb, feedforward networks handle tabular data, CNNs handle visual inputs, RNNs handle sequences, and GNNs handle relational data. The word deep simply refers to adding more hidden layers. Depth can improve performance but also increases training time and risk of overfitting.
Understanding these types not only clarifies the technical choices but also grounds your answer to what is neural network in concrete use cases. When a marketing colleague hears the term, you can explain that for a photo app it might mean a convolutional network, while for a language assistant it might mean a sequence model.
Implementation lifecycle: from idea to production
Implementing a neural network is a process that spans idea, data, model development and deployment. Here’s a high‑level path for product and design teams:
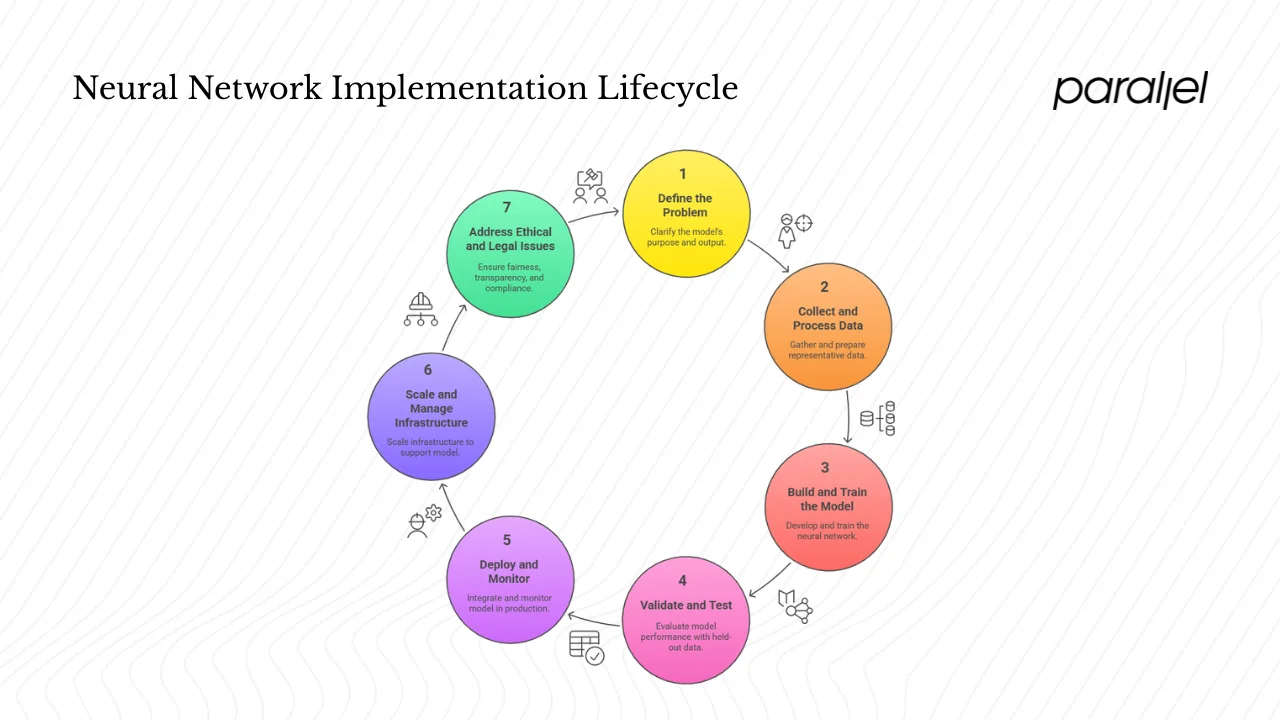
- Define the problem. Clarify what pattern you want the model to learn and what output is useful. Is the goal to classify images, predict churn, or generate responses? A good problem statement guides data collection and evaluation metrics.
- Collect and process data. Gather representative training data. Data should cover the range of scenarios the model will face; biases or gaps in data lead to biased outcomes. Tasks include cleaning, labeling and splitting the data into training, validation and test sets. Design teams should think about how users will contribute data and whether permission and privacy are handled properly.
- Build and train the model. Decide on an architecture (number of layers, type of network, activation functions). Data scientists then train the model by feeding it examples, performing forward and backward passes, and tuning weights using optimisation algorithms. Early prototypes often start small to validate feasibility before scaling up. Evaluating performance on a validation set helps avoid overfitting.
- Validate and test. Use held‑out data to check how well the model generalizes. Define success metrics (accuracy, precision, recall, F1‑score). For design features, consider user‑experience metrics such as satisfaction or task completion rates. Iterate on the model and data based on feedback.
- Deploy and monitor. Integrate the trained model into your application through an API or service. Monitor predictions and performance in production, as data distributions may change over time (data drift). Have a plan to retrain or update the model when performance degrades.
- Scale and manage infrastructure. Consider how to host the model—on‑device for low latency, or in the cloud for flexibility. Training large models can be costly; using pre‑trained models and transfer learning can reduce expenses. For early‑stage teams, managed services from cloud providers can simplify scaling.
- Address ethical and legal issues. Data privacy, fairness and transparency matter. Neural networks can inadvertently encode biases present in training data. Cross‑functional teams should evaluate outcomes for fairness and ensure compliance with data‑protection regulations. Documenting how the model was developed and tested helps build trust.
Throughout this lifecycle it helps to remind yourself what is neural network and what it is not. The network is a tool—an adaptable function approximator—not a magic wand. Its behaviour is shaped by data, design choices and ongoing monitoring. Keeping that in mind prevents unrealistic expectations and helps teams balance ambition with caution.
Designers and product managers play a critical role throughout this lifecycle. They help define the problem from a user perspective, ensure data represents real user scenarios, and integrate model outputs into clear, usable interfaces. They also balance the benefits of automation against potential harms, such as false positives or user confusion.
Challenges, limitations and best practices
Despite their power, neural networks are not a panacea. Several challenges and limitations must be considered:
- Data hunger: Neural networks often require large amounts of labelled data to learn effectively. Collecting and labeling sufficient examples can be expensive and time‑consuming, particularly for specialised domains.
- Compute and energy costs: Training deep networks can be computationally intensive, requiring GPUs or specialized hardware. Startups must account for training time, hardware costs and environmental impact.
- Interpretability: Neural networks are complex; it can be hard to understand why they make certain decisions. This “black box” issue complicates regulatory compliance and user trust. Techniques like LIME or SHAP can provide some interpretability, but simpler models might be preferable when transparency is critical.
- Overfitting and generalization: Without careful regularisation, networks may memorise training data and perform poorly on new data. Dropout, weight decay, and cross‑validation help, but there is no guarantee. GeeksforGeeks notes that poorly initialised weights and biases can slow learning and lead to suboptimal results.
- Bias in data: Models learn whatever patterns exist in their training data. If the data reflects societal biases, the model will replicate them. Diverse and representative datasets, fairness metrics and human oversight are essential.
- Resource trade‑offs: Sometimes simpler machine‑learning methods (decision trees, logistic regression) are adequate. Neural networks should be justified by improved performance on problems where their complexity is warranted.
Best practices for early‑stage teams include starting with baseline models to set expectations, focusing on data quality, and involving designers and product managers early. Experiment with simple architectures first before moving to deeper models. Use cross‑disciplinary reviews to evaluate the ethical implications. Document assumptions, data sources and model changes. And remember that shipping a well‑understood simple model often beats chasing the latest research fad.
Real‑world examples and case studies
Concrete examples help demystify neural networks. Here are a few:
- Email spam detection. Early neural networks were used to classify emails as spam or not spam. A feedforward network processes word counts from emails, multiplies them by weights and biases learned during training, and outputs a probability. When the output exceeds a threshold, the email is flagged. This example shows how even simple architectures can handle high‑dimensional, unstructured text data.
- Image classification. CNNs analyze images by scanning for features. TechTarget describes how CNNs use multiple hidden layers to perform mathematical functions that identify patterns and extract relevant features from input images. In manufacturing, a CNN can detect defective products on a production line, freeing humans from repetitive inspection tasks. In healthcare, CNNs can examine radiology images to assist doctors in spotting tumours.
- Voice recognition and chatbots. Recurrent neural networks and transformers convert spoken language into text and understand context. This powers voice assistants, transcription services and conversational bots that handle customer support. In startups, chatbots can automate tier‑1 support, while human agents handle complex issues.
- Recommendation systems. Streaming services and e‑commerce platforms use neural networks to suggest content or products. They learn latent representations of users and items and then predict which combinations will work. When integrated thoughtfully into the user interface, suggestion engines can increase engagement and reduce churn.
- Anomaly detection. In operations and security, neural networks identify unusual patterns. For instance, a model trained on normal network traffic can detect anomalies signaling a cyberattack. In finance, networks monitor transaction patterns to flag fraud.
The GeeksforGeeks article provides real‑world applications where weights and biases help networks focus on important features: in image recognition, the network emphasises pixels that correspond to ears, whiskers and eyes when identifying cats; in natural‑language processing, it emphasises specific words to understand sentiment; in autonomous vehicles, it emphasises sensors recognising pedestrians and road signs; and in medical diagnosis, it emphasises areas indicating tumours. These examples show how adjusting weights and biases shapes the model’s perception of importance.
For product leaders evaluating such features, consider success metrics: classification accuracy, reduced time to perform tasks, or improved user satisfaction. Also evaluate the cost of false positives and negatives. A recommendation system that occasionally suggests an irrelevant product might be acceptable; an anomaly detector that misses fraud is not. Understanding these trade‑offs helps you allocate resources wisely.
Future trends and what to watch
The field is changing fast. Recent models like transformers have reshaped natural‑language processing. Graph neural networks open new possibilities for working with relational data. We’re also seeing a shift towards foundation models—large pretrained models that can be fine‑tuned for specific tasks. These models, built by companies with massive computational resources, are becoming accessible through APIs. This reduces the barrier to entry for startups, who can integrate powerful capabilities without training from scratch.
AutoML and low‑code platforms are making it easier to experiment with neural networks. Managed services handle training, tuning and deployment, allowing teams with limited machine‑learning expertise to implement advanced features. However, the rise of generative models also raises concerns about hallucination, misuse and intellectual‑property rights. Ethical design remains critical: transparency, consent and user control should guide product decisions.
For early‑stage teams, the prudent path is to use these tools thoughtfully. Start with clear use cases and data strategies. Consider leveraging pretrained models through service providers. Focus on user problems rather than chasing hype. As the Salesforce Ventures workshop participants put it, setting the right work environment, encouraging experiments and framing artificial‑intelligence adoption as a way to augment human roles improves acceptance. They also stress choosing tools intentionally and re‑evaluating workflows to integrate automation effectively.
Conclusion
Understanding what a neural network is equips founders, product managers and designers to make smarter decisions about artificial‑intelligence‑powered features. A neural network is essentially a model that stacks simple computational units—neurons—in layers, assigns weights and biases to connections, applies activation functions to introduce non‑linearity and learns through forward and backward passes. These models excel at recognising patterns in unstructured data, enabling suggestion engines, vision applications and conversational interfaces.
For startup teams, neural networks present both opportunities and challenges. They allow you to process complex data and differentiate your product, but they demand data readiness, infrastructure and careful consideration of ethical issues. Begin with clear problem statements and representative datasets. Prototype simple models, validate their impact on user experience, and iterate. Collaborate across design, product and engineering to ensure that model outputs are understandable and beneficial. And keep an eye on emerging architectures and tools that lower barriers to entry while raising questions about responsibility.
By demystifying neural networks and grounding them in real applications, product teams can move from passive observers to informed participants in the artificial‑intelligence conversation. Keep asking yourself what is neural network as you encounter new tools and jargon; the answer doesn’t change, but your perspective deepens. This understanding helps you steer features that harness the strengths of neural networks while respecting users and aligning with business goals. The field will continue to change, but a solid grasp of the fundamentals will anchor your decisions.
FAQ
1) What is a neural network in simple words?
A neural network is a computer model made up of many simple processing units called neurons. These neurons are arranged in layers and connected by adjustable strengths (weights) and offsets (biases). During training, the network looks at examples and adjusts those strengths so that it can recognise patterns or make predictions. Think of it as a system that learns by example.
2) What is an example of a neural network?
One common example is email spam detection. A neural network can look at the words in an email, multiply them by learned weights and biases, and output a score indicating how likely the message is to be spam. When the score is above a certain threshold, the message goes to the junk folder. Other examples include image classification using convolutional networks, voice recognition using sequence models and suggestion engines on streaming services.
3) Is ChatGPT a neural network?
Yes. ChatGPT is built on large neural‑network architectures known as transformers, which are types of deep learning models designed for language. These models contain billions of parameters (weights) and learn from vast datasets to generate coherent text. While ChatGPT incorporates additional components and training strategies, at its core it uses neural‑network principles: layers of neurons, adjustable weights and non‑linear activations.
4) What is the difference between artificial intelligence and neural networks?
Artificial intelligence is the broad field of making machines mimic human capabilities like reasoning, learning and perception. Neural networks are one technique within that field. They belong to machine learning and, more specifically, to deep learning. While artificial intelligence includes rule‑based systems, search algorithms and symbolic reasoning, neural networks rely on data and continuous optimization to learn patterns. In other words, neural networks are one way to build artificial‑intelligence systems.

check out these related blogs










































































.avif)
























